
GEB by Douglas R. Hofstadter
This book is a joy. Though I have read but two thirds of it, here I am to regurgitate it’s key points and even try to map them onto an adjacent domain — modern artificial intelligence. Gödel, Escher, Bach by Douglas Hofstadter is a masterpiece of instructive writing if nothing else which covers the authors understanding of consciousness from a computer science, math, and philosophical perspectives. Along with a strong understanding of neuroscience no doubt, though the book does a good job staying clear of this underdeveloped field (twas written in the year of our Lord: 1979). Though I will talk here about the books core concept (or better yet an LLM could summaries it for you) nothing compares to the reading of it for how well the author weaves concepts together, and how cleverly they are written of. There are lots or dialogues, diagrams, images (mostly Escher’s works), poetry, sheet music, and even blocks of code. It is beautiful.

The core idea is this: consciousness is born of self-reference. The book walks through self-reference and recursion as they appear in various works, phenomenon, and systems. Chief among these of course are the Incompleteness Theorem of Kurt Gödel, the art of M.C Escher, and the music of J.S Bach, which each in turn seem to embed self-reference and paradox.
The book is thought provoking in a strange way; in that it leaves you thinking about thought, and having some extra understanding with which to do so. While refreshingly also steering away from neuroscience and philosophy, and conventional discussion about the nature of consciousness; it does however in a general way explore whether mind and matter are essentially different / separate. For your information: this concept is called dualism, and it is rejected by the book, I think, as I said; I haven’t finished it. But allow me to write this anyway for my own good.
How Agentic AI Works
uuuuuhhgh, whats agentic AI? Agentic AI is when the LLM system you are using doesn’t respond to you immediately, instead it takes its own output and puts it back into the LLM.
Wait, wait, wait what use would that be? Well first you should understand that the LLMs are not just seeing as input what you put into the text box in the chat window + the chat history. Your message, and the chat history, are wrapped in a prompt, something like this:
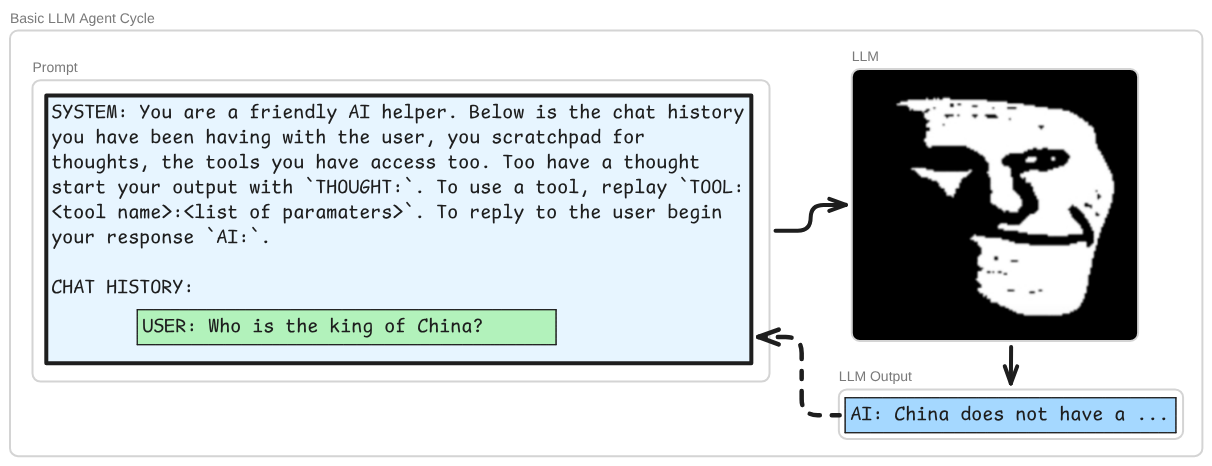
There are two more basic components to such a system; thoughts and tools. Given the full prompt, plus the users next input, the LLM may decide that it had better ’think’ a couple of times before it tries to answer the user:
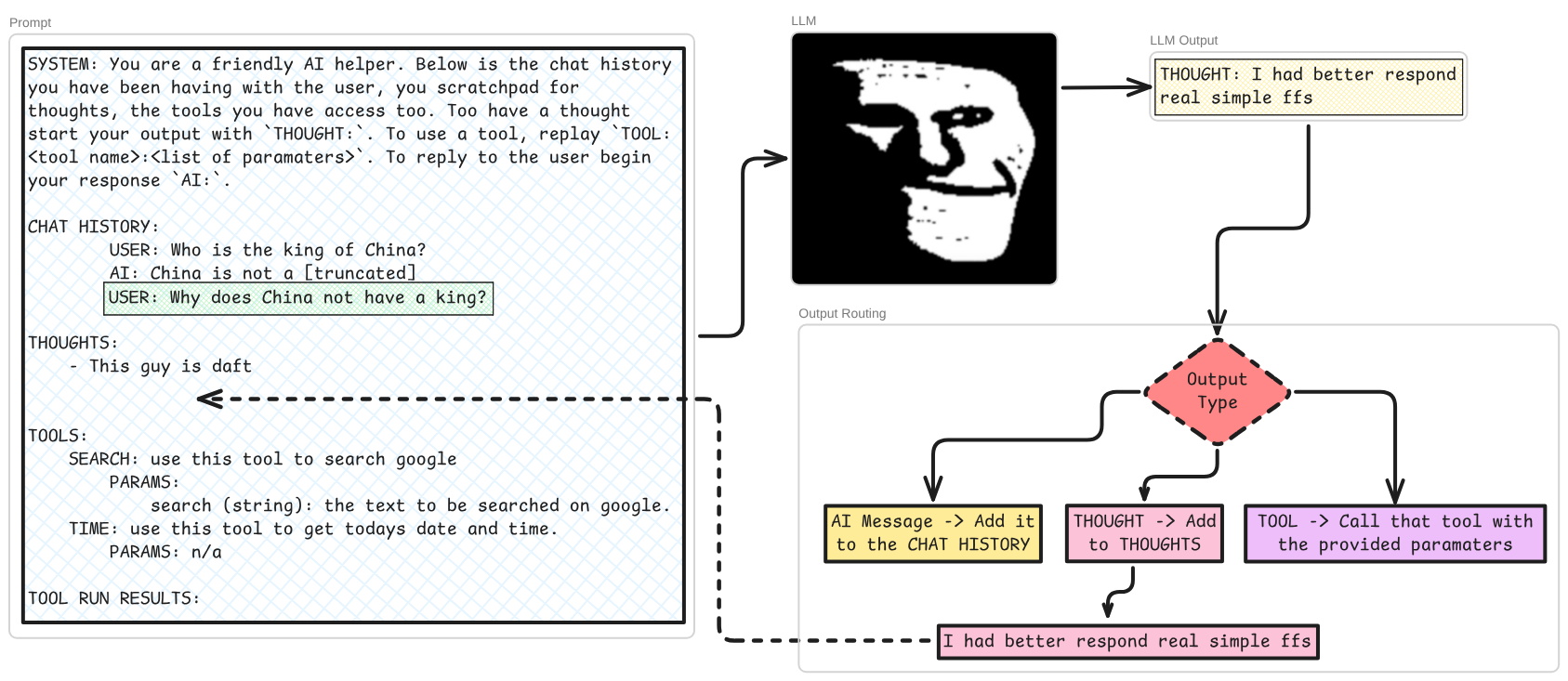
It may also wish to use a ’tool’. Tools are functions in code which can be used by the agent loop’s logic, either directly or via CLI (this sentence was for Conor). This is so the next pass through the LLM’s has more information with which to generate the output. Tools can be virtually anything you can think of doing with a computer, but the most common tool would be some implementation of using a search engine. Something like this:
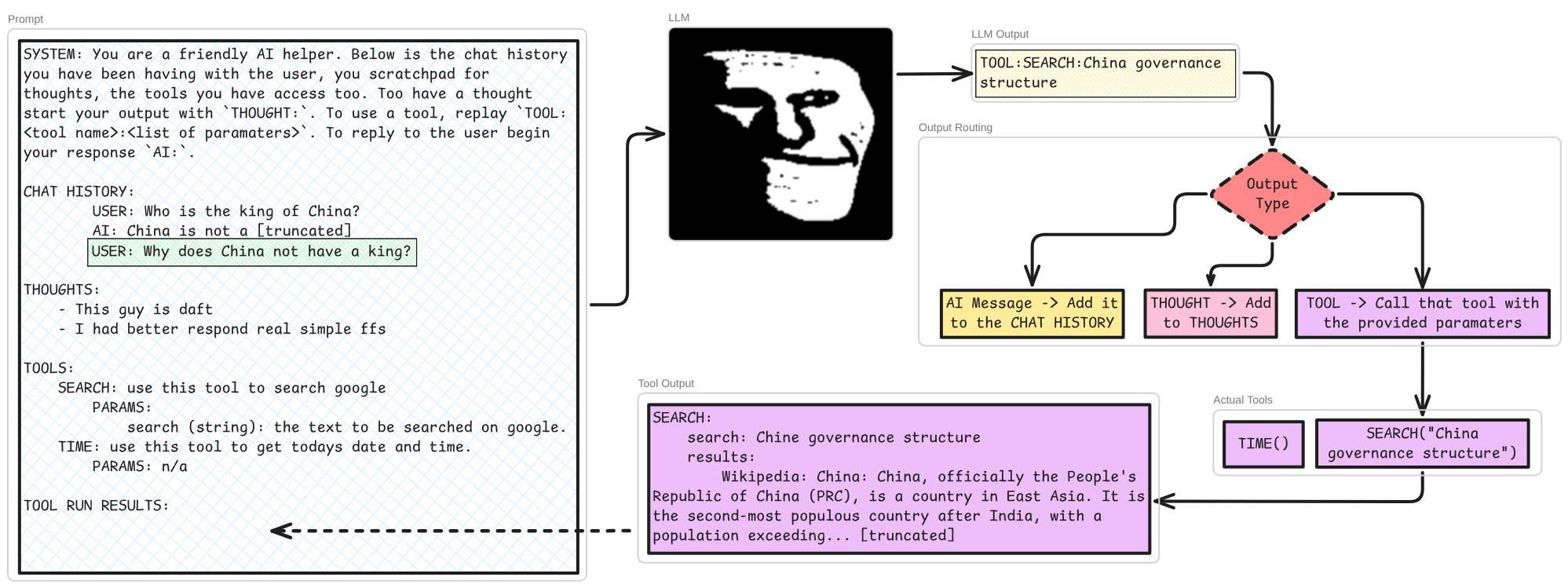
Each of these steps my recur a number of times -> multiple thoughts, multiple tool calls / internet searches, maybe thoughts after tool usage, but the system in our basic example knows that it is time to actually respond to the user whenever the LLM outputs something beginning AI:
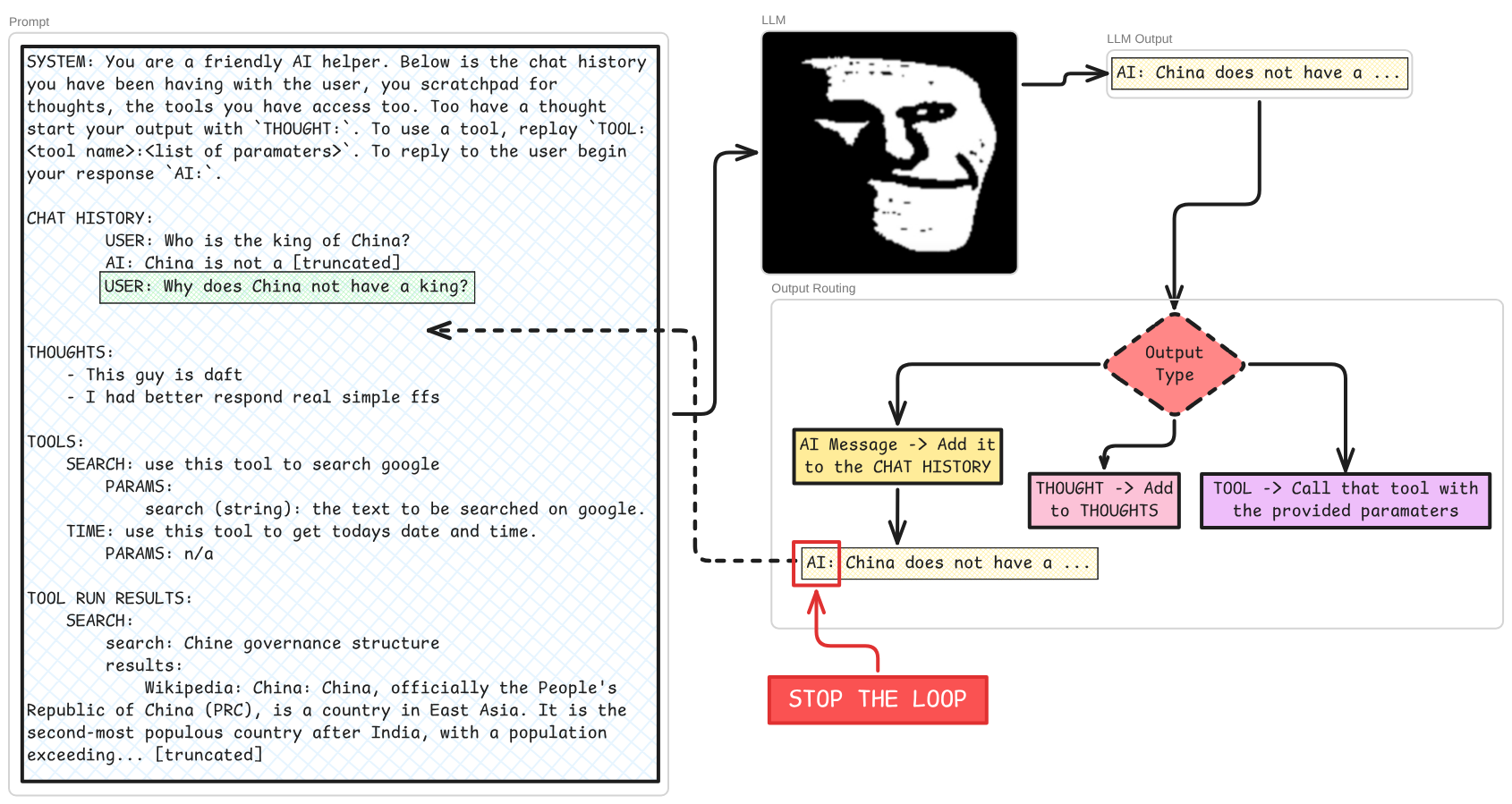
Above is an rough outline of how LLM agents work, I’ve kept it simple in a bid to make it timeless but chances are it’ll be out of date before I click publish on this. What I would like to point out about this loop at this point is that though feeds into itself, it is rigid, it’s form is locked and without a human effort to change the code / logic of it, it’s complexity is limited to the problem space it exists in. Yet one might argue that the space in which it exists is all of the internet if it has search tools, and virtually all of the books and article and public code repositories. Well, yes, but we’re here to talk about ‘strange loopedness’, and these facts of the agents loop’s being aren’t enough to warrant that label in my opinion. But lets get some more understanding before we come to that…
I don’t really know what an LLM is… You might remember functions, graphs, statistics from school, well artificial neural networks does this lots and fast. In the beginning, x predicted y via a line on a graph (y=mx+b). Then there was a long period of weird happenings in the machine learning field. After that we started using the artificial neural network to do predictive statistics. It works like this; the inputs are converted into numbers, this can be awkward or straightforward depending on the nature of the problem we are working with. If the ANN’s task is to take pictures of characters and output its guess as to which alphanumeric character is in the picture, then it’s easy enough because the input is just a grid of pixel colour values and the output is a list of characters, a, b, c, etc. if the image is 50x50 pixels then our ANN will have 2500 inputs and say 26+26+10 outputs (you’re a smart boy). Our inputs correspond to pixels, our output correspond to characters; these are the ’neurons’ in the first and final layers. However, what makes this a ‘deep’ neural network is the use of ‘hidden’ layers, where neurons exist purely to encode the meaning of the potential inputted data.
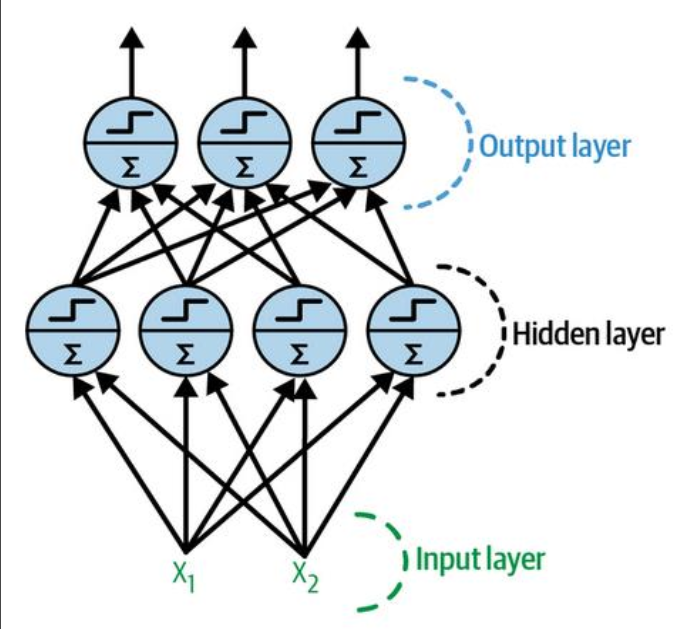
So a neuron in an ANN takes in the values of every neuron in the previous layer adjusted buy some weight, sums them, adds its bias, then puts the output of this through an activation function. This is a load of linear algebra and is a very elegant idea indeed but I shall pass over the details… The values for the weights and biases come from the training process. Wherein the values start somewhere arbitrary, and a forward pass is made through the ANN, then the output (which will be very wrong in the beginning most likely) is measured against the desired output. The difference between the output for this piece of data, and what would have been the correct output is then used propagate little changes to the weights and biases backwards. This is called backpropagation :)
All well and good this is for problems where the input predicts a single output, but what if we want a sequence of outputs, like the next couple of days weather, or words in a sentence (:o), frames in a video clip (:O). And from this need the Recurrent Neural Network was born: by having one of the input neurons be the output of the last forward pass through the NN. This is called auto-regression - the model feeds on it’s own output… sounds familiar…
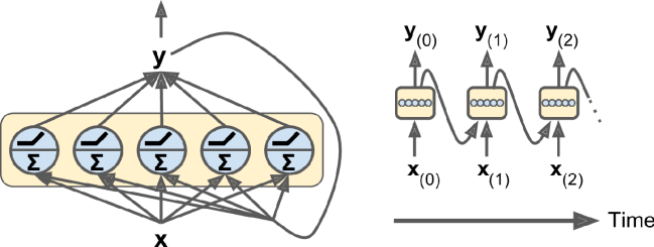
The problem with RNN is that the with each iteration, the significance of the past outputs diminishes (this is called the vanishing gradient problem), the most recent output carries the most information forward to the next iteration. To combat this issue: The LSTM Model, where — via some slightly too complex to describe maths — the model gets to decided what information from the past to pass through to the next pass. You might be thinking ’this must be it then, this is how LLMs were solved’. NO! Silly boy. The problem with LSTM is that — again for reasons beyond our scope here — it cannot be scaled, it is a sequential model by nature, so it cannot be parallelized (to get a grasp of sequential vs parallel problems in computer science, one might imagine a big strong man trying to flip a car by hand, versus 20 such men). The complicated pluming and math in the LSTM was in effect replaced by the ATTENTION mechanism, invented and coined by researchers at Google in 2017. This model’s architecture (the ’transformer’, yes seriously) was introduced in a paper titled ‘Attention is All You Need’ which has been cited hundreds of thousand of times, and frankly can be considered the most significant scientific publication in living memory. And whats most important here is that the transformer can be trained, and inference can be drawn from it, in parallel, using highly parallelised compute (GPUs).
![]()
The Strange Loop
Turning our attention back to the Strange Loop proposed by Hofstadter in GEB as a framework to understand consciousness, lets talk a little more about what it is. The human brain does not in the beginning of it’s life have an ego, a self, an I. This comes about because 1) our thoughts strengthen the neurons they pass though each time they do so, and 2) our brain neurological circuitry is so complex such that when these thoughts pass through, they can loop back upon themselves and become necessarily self-referential and paradoxical. And at some stage become able to represent itself. Interestingly a certain little Prince among our readership remembers this phase change coming on all of a sudden… food for thought. I use the term phase change intentionally, as in physics and chemistry this term describes the transition of a substance from one state to another, like ice to liquid, or liquid to gas. My very superficial reading in the subjects of consciousness, psychology, and chaos theory have left me with a physics-based-meta-understanding of mind and consciousness to be highly analogous to fluid dynamics.
I’m running out of time to submit this, I must hasten to make my point. The reason why I don’t believe an Agentic AI system, as they exist today in mid-2026 can be considered conscious, is two fold. Firstly, they are entirely language based, and I feel like I have an under explored contention with Hofstadter’s framing of consciousness… Nay not just his but most theories I have encountered… in that they rely overmuch on language as a central component of it. But above this poorly-thought-through reason is that I believe a system that is hard coded with meeting a stopping condition cannot be reconciled with the strange-loop. The strange-loop is a continuous process, that, when healthy at least, seek to expand and enrich itself. Where as the AI Agent wants to get to it stopping condition. This discreteness goes for both the LLM level, and the agent loop level. They want to get it done, but we hope it never ends….
Kids, maybe don’t try polymathy.
And stay away from yourself.
Sources and Resources
Some diagrams from: Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition - Aurélien Géron
P.S; If you have the slightest interest in ML, AI, LLM, etc these are must watch video series’ for setting foundations in those areas.